漫谈推荐系统源码:NextRec
如果觉得不错或感兴趣的话,可以star一下,感谢!
元旦假期刚好把前几年的PEPNET跟进一下。这篇文章由快手团队发布于2023年,面向多场景多任务建模,并在快手全量上线。
多场景多任务其实就是在之前的多任务建模下增加了一个维度,原先的多任务可以对应单个页面下对不同产品的点击率,注册率,转化率;而多场景就在不同页面下做多任务建模,在营销场景下,可以对应不同营销方式的多环节转化目标。
这一任务的出发点主要是以下几点:
- 每个场景单独建模,需要维护的模型太多,且样本无法共用,这也是最初多任务建模试图解决的问题。可以看到,业务上的不断演进也推动着算法理论的跟进。
- 依旧是跷跷板问题,多任务场景下,不同任务会有跷跷板问题,即一个任务训好了,另一个任务变差了。之前很多模型都尝试对此做出改进,现在由于多了多场景这个维度,因此也多了不同场景的跷跷板问题(被称为双跷跷板),即有些场景样本量大,目标更好学,小样本场景就得不到充分学习。
模型架构
如何解决跷跷板问题,PEPNET尝试增加对个性化的先验信息的学习。什么体现了个性化的信息?那就是Embedding。一个Embedding里,并不是所有信息都要学习的,而是不同场景找需要的Embedding的一部分。如何选择需要的Embedding部分?那就需要门控单元。什么时候需要门控单元?我们不仅需要为不同场景搞准备门控单元,还要为不同任务准备门控单元,最终的目的都是让模型针对性的拿到需要的Embedding和子网络参数。这就是PEPNET的全名:Parameter and Embedding Personalized Network。
从参数学习的角度上,有一点类似POSO,POSO尝试用不同分布的PC特征来学习一些先验的信息。
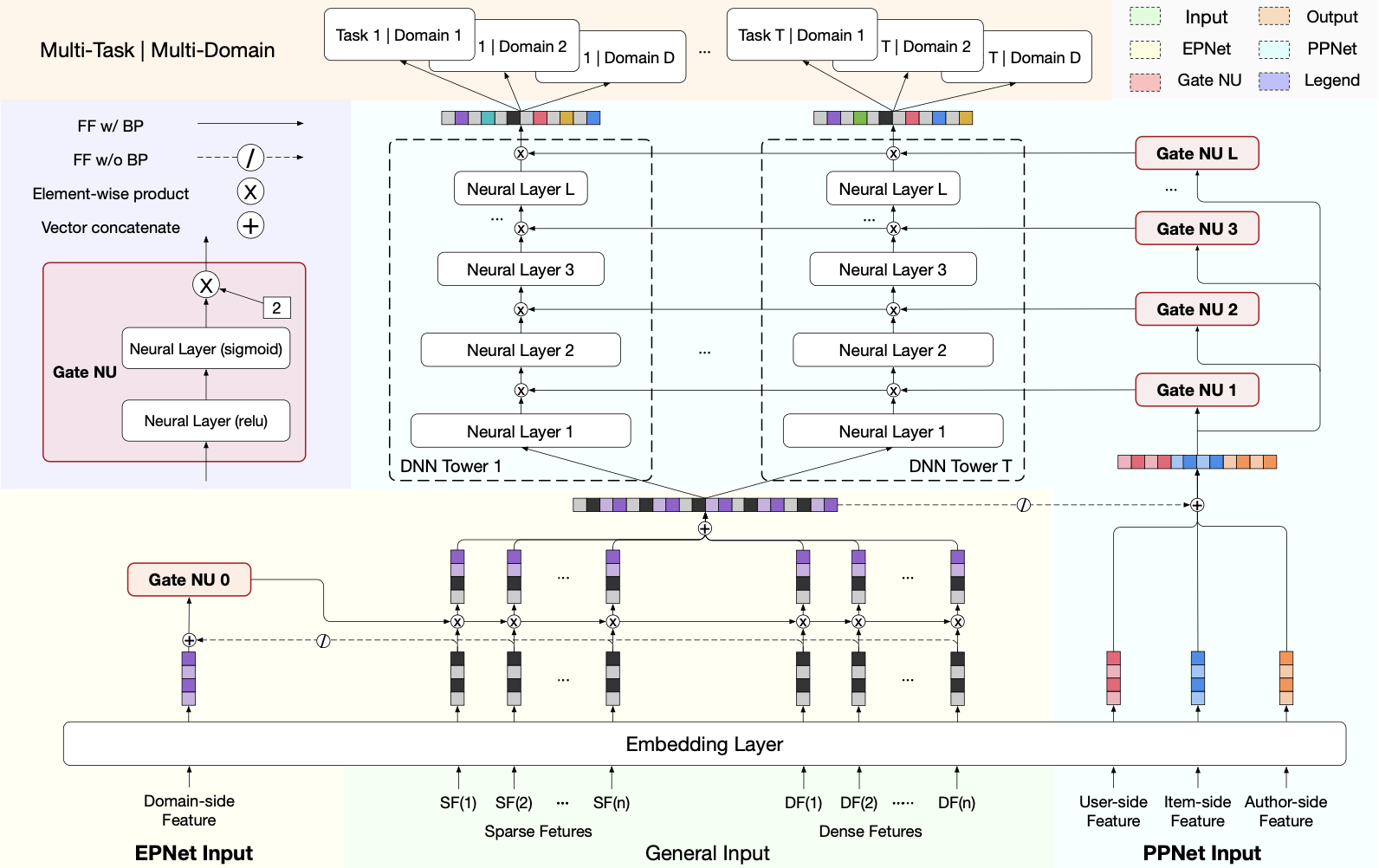
上图是PEPNET的架构图,有几个东西是我们没见过的:Gate NU,EPNet和PPNet。
Gate NU是一个缩放门控单元,两层全连接,最后一层用sigmoid,然后用一个缩放因子2进行逐元素相乘。它的结果是对输入的每个元素的加权比重,例如[2,4,1]就代表着Embedding对应位置的加权比例。
公式如下: $$ x_1 = ReLU(x_0 W_0 + b_0) $$
$$ x_1 = 2 \cdot Sigmoid(x_1 W_1 + b_1) $$
在图例里,domin特征(例如不同的场景ID或场景特有特征)作为输入,通过Gate NU得到门控网络的加权值,这个加权值和Embedding层进行逐元素相乘后,得到不同场景下更重要的Embedding,这个组件就是EPNet(Embedding Personalized Network)。这个组件的含义就是指,将同一个Embedding在不同场景下进行映射。为了让EPNet不影响底层共享Embedding的学习,在计算门控结果时让共享Embedding层的梯度不参与反向传播。
PPNet(Parameter Personalized Network),它接收了完整的特征,包括加权后的Embedding特征,各种ID,随后再通过Gate NU加权,传入下一层。多次层叠,这就构成了一个所谓定制化参数的DNN。
代码实现
在NextRec中实现了PEPNET,只需要from nextrec.models.multi_task.pepnet import PEPNet即可调用。我们可以看一下源码。
首先是PEPNet的实现:
class PEPNet(BaseModel):
"""
PEPNet: feature-gated multi-task tower with task-conditioned gates.
"""
def __init__(
self,
dense_features: list[DenseFeature] | None = None,
sparse_features: list[SparseFeature] | None = None,
sequence_features: list[SequenceFeature] | None = None,
target: list[str] | str | None = None,
task: TaskTypeName | list[TaskTypeName] | None = None,
mlp_params: dict | None = {"hidden_dims": [256, 128], "activation": "relu", "dropout": 0.0},
feature_gate_mlp_params: dict | None = {"hidden_dim": 128, "activation": "relu", "dropout": 0.0, "use_bn": False},
gate_mlp_params: dict | None = {"hidden_dim": None, "activation": "relu", "dropout": 0.0, "use_bn": False},
domain_features: list[str] | str | None = None, # 对应文中的场景特征
user_features: list[str] | str | None = None, # 用户特征
item_features: list[str] | str | None = None, # 物品特征
use_bias: bool = True,
**kwargs,
) -> None:
self.nums_task = len(target) if target else 1
super().__init__(
dense_features=dense_features,
sparse_features=sparse_features,
sequence_features=sequence_features,
target=target,
task=task,
**kwargs,
)
if isinstance(domain_features, str):
domain_features = [domain_features]
if isinstance(user_features, str):
user_features = [user_features]
if isinstance(item_features, str):
item_features = [item_features]
self.scene_feature_names = list(domain_features or [])
self.user_feature_names = list(user_features or [])
self.item_feature_names = list(item_features or [])
if not self.scene_feature_names:
raise ValueError("PepNet requires at least one scene feature name.")
self.domain_features = select_features(
self.all_features, self.scene_feature_names, "domain_features"
)
self.user_features = select_features(
self.all_features, self.user_feature_names, "user_features"
)
self.item_features = select_features(
self.all_features, self.item_feature_names, "item_features"
)
if not self.all_features:
raise ValueError("PepNet requires at least one input feature.")
self.embedding = EmbeddingLayer(features=self.all_features)
input_dim = self.embedding.get_input_dim(self.all_features)
domain_dim = self.embedding.get_input_dim(self.domain_features)
user_dim = (
self.embedding.get_input_dim(self.user_features)
if self.user_features
else 0
)
item_dim = (
self.embedding.get_input_dim(self.item_features)
if self.item_features
else 0
)
task_dim = domain_dim + user_dim + item_dim
# EPNet: shared feature-level gate (paper's EPNet).
# 这里我们用一个门控单元定义epnet,输出input_dim大小的一条 gate 向量
self.epnet = GateMLP(
input_dim=input_dim + domain_dim,
hidden_dim=feature_gate_mlp_params["hidden_dim"],
output_dim=input_dim,
activation=feature_gate_mlp_params["activation"],
dropout=feature_gate_mlp_params["dropout"],
use_bn=feature_gate_mlp_params["use_bn"],
scale_factor=2.0,
)
# PPNet: per-task gated towers (paper's PPNet).
self.ppnet_blocks = nn.ModuleList(
[
PPNet(
input_dim=input_dim,
output_dim=1,
gate_input_dim=input_dim + task_dim,
mlp_params=mlp_params,
gate_mlp_params=gate_mlp_params,
use_bias=use_bias,
)
for _ in range(self.nums_task)
]
)
self.prediction_layer = TaskHead(
task_type=self.task, task_dims=[1] * self.nums_task
)
# 用于记录grad norm和正则化的一些配置
self.grad_norm_shared_modules = ["embedding", "epnet"]
self.register_regularization_weights(
embedding_attr="embedding", include_modules=["epnet", "ppnet_blocks"]
)
def forward(self, x: dict[str, torch.Tensor]) -> torch.Tensor:
dnn_input = self.embedding(x=x, features=self.all_features, squeeze_dim=True)
# 原始场景特征embedding梯度不更新
domain_emb = self.embedding(
x=x, features=self.domain_features, squeeze_dim=True
).detach()
# 完整的特征,包括加权后的Embedding特征,各种ID,随后再通过Gate NU加权构建PPNET
task_parts = [domain_emb]
if self.user_features:
task_parts.append(
self.embedding(
x=x, features=self.user_features, squeeze_dim=True
).detach()
)
if self.item_features:
task_parts.append(
self.embedding(
x=x, features=self.item_features, squeeze_dim=True
).detach()
)
task_sf_emb = torch.cat(task_parts, dim=-1)
gate_input = torch.cat([dnn_input.detach(), domain_emb], dim=-1)
dnn_input = self.epnet(gate_input) * dnn_input
task_logits = []
for block in self.ppnet_blocks:
task_logits.append(block(o_ep=dnn_input, o_prior=task_sf_emb))
y = torch.cat(task_logits, dim=1)
return self.prediction_layer(y)
然后是PPNet:
class PPNet(nn.Module):
"""
PPNet: per-task tower with layer-wise gates conditioned on task context.
"""
def __init__(
self,
input_dim: int,
output_dim: int,
gate_input_dim: int,
mlp_params: dict | None = None,
gate_mlp_params: dict | None = None,
use_bias: bool = True,
) -> None:
super().__init__()
mlp_params = mlp_params or {}
gate_mlp_params = gate_mlp_params or {}
hidden_units = mlp_params["hidden_dims"]
norm_type = mlp_params["norm_type"]
if isinstance(mlp_params["dropout"], list):
if len(mlp_params["dropout"]) != len(hidden_units):
raise ValueError("dropout_rates length must match hidden_units length.")
dropout_list = mlp_params["dropout"]
else:
dropout_list = [mlp_params["dropout"]] * len(hidden_units)
if isinstance(mlp_params["activation"], list):
if len(mlp_params["activation"]) != len(hidden_units):
raise ValueError(
"hidden_activations length must match hidden_units length."
)
activation_list = mlp_params["activation"]
else:
activation_list = [mlp_params["activation"]] * len(hidden_units)
self.gate_layers = nn.ModuleList()
self.mlp_layers = nn.ModuleList()
layer_units = [input_dim] + hidden_units
for idx in range(len(layer_units) - 1):
dense_layers: list[nn.Module] = [
nn.Linear(layer_units[idx], layer_units[idx + 1], bias=use_bias)
]
if norm_type == "batch_norm":
dense_layers.append(nn.BatchNorm1d(layer_units[idx + 1]))
dense_layers.append(activation_layer(activation_list[idx]))
if dropout_list[idx] > 0:
dense_layers.append(nn.Dropout(p=dropout_list[idx]))
# 门控加权单元
self.gate_layers.append(
GateMLP(
input_dim=gate_input_dim,
hidden_dim=gate_mlp_params["hidden_dim"],
output_dim=layer_units[idx],
activation=gate_mlp_params["activation"],
dropout=gate_mlp_params["dropout"],
use_bn=gate_mlp_params["use_bn"],
scale_factor=2.0,
)
)
self.mlp_layers.append(nn.Sequential(*dense_layers))
# 最后一层不做scale
self.gate_layers.append(
GateMLP(
input_dim=gate_input_dim,
hidden_dim=gate_mlp_params["hidden_dim"],
output_dim=layer_units[-1],
activation=gate_mlp_params["activation"],
dropout=gate_mlp_params["dropout"],
use_bn=gate_mlp_params["use_bn"],
scale_factor=1.0,
)
)
self.mlp_layers.append(nn.Linear(layer_units[-1], output_dim, bias=use_bias))
def forward(self, o_ep: torch.Tensor, o_prior: torch.Tensor) -> torch.Tensor:
"""
o_ep: EPNet output embedding (will be stop-grad in gate input)
o_prior: prior/task context embedding
"""
gate_input = torch.cat([o_prior, o_ep.detach()], dim=-1)
hidden = o_ep
for gate, mlp in zip(self.gate_layers, self.mlp_layers):
# 每一层的个性化加权
gw = gate(gate_input)
hidden = mlp(hidden * gw)
return hidden2026/1/3 于苏州