金融科技的机器学习?
懒加载的痛苦
最近的工作里,花在写模型架构和调参的时间越来越少了,与之相对的是写特征处理代码的时间成倍的增加了。spark固然能高效处理大数据,但是让人最挫败也是它的懒加载。当我辛辛苦苦写好的数据处理代码,在跑了5小时以后存hdfs时突然报错,没有python的调用栈报错,而是一堆转译java时的报错,这不禁让我感到深深的无力感。
每次执行cell都是一次俄罗斯轮盘赌,赌接下来的几个小时是否会有收获,还是无功而返。
工作里的数据预处理
和比赛完全不一样,曾经的我以为数据预处理,无非就是缺失值和离群值的调整和一些类别标签的折腾,而实际工作里这已经是很干净的数据了。更多的是不等长的序列,序列里充斥着缺失值,字符串。稀疏标签和乱七八糟的embedding向量拼接在一起,一边是极大量的0,另一边是上百维的浮点数,有的时候你也不知道特征重要性里,某个embedding向量里的一个vector为啥排序这么高。
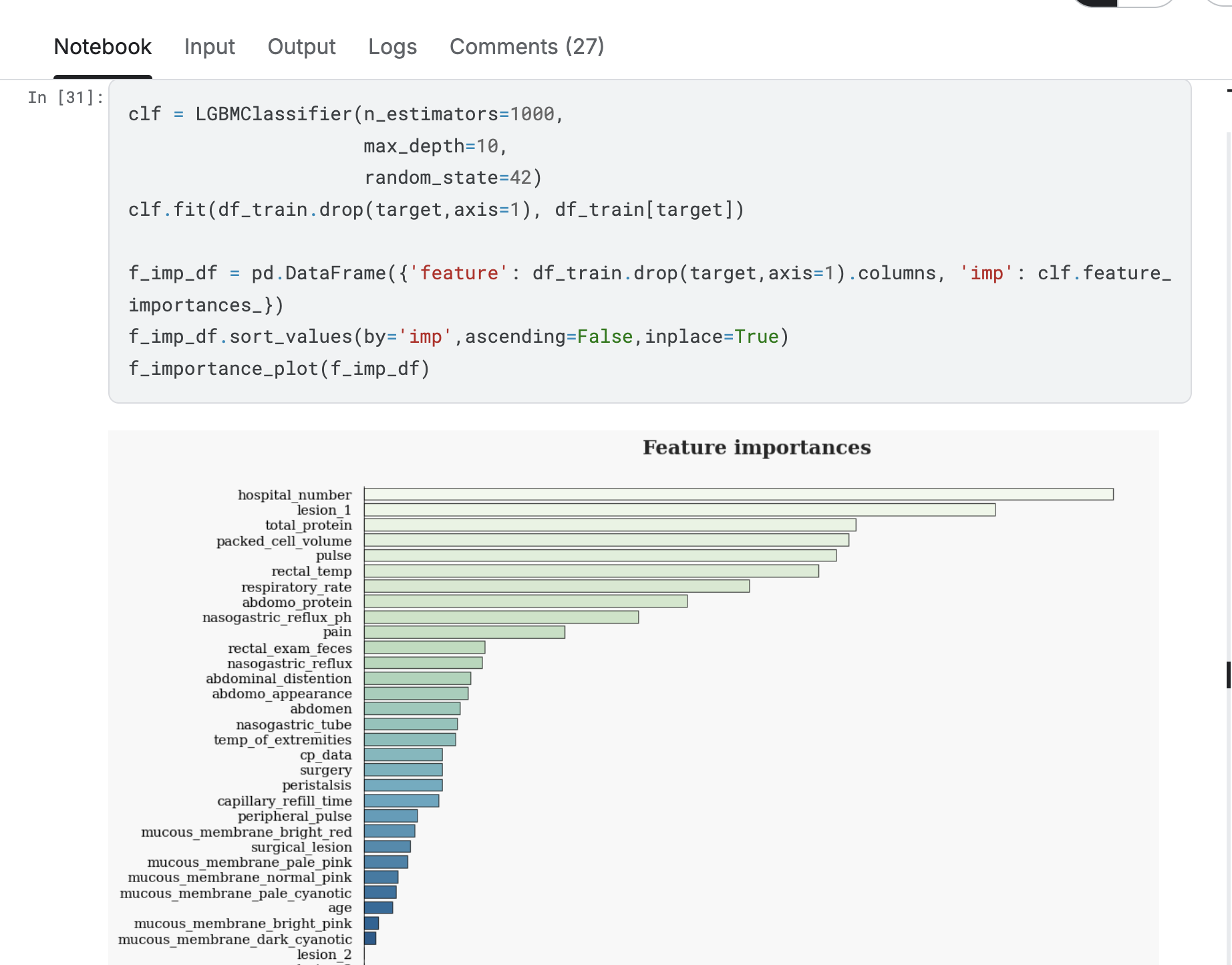
高维和模型的取舍
当维度提高到几千以上时,模型的选择已经不多了。尤其是在需要考虑到分布式训练的场景,要保证效果,只能从树模型,线性模型和DNN里选。如果我们还想追求虚无缥缈的模型可解释性,那只有前两者可以选了。考虑到训练一次的时间成本,所谓的调参也没有了,我只能寄希望于这次的树模型分裂点足够关键,或者是这次随机负样本的特征足够全,足以得到一个与正样本拥有明确间隔的平面or超平面。
负样本的选择是一个玄学问题,这是我的结论。阿弥陀佛。
现实就是小样本与样本不平衡
与高维相对的是为数不多的样本。如果有近万维的特征,和勉强过万的正样本,一切模型层面的架构奇淫巧技都没有那么重要了,你不会觉得一个模型在这个场景下,还可以通过叠高layer数量就能获得指标提升,这就是必须接受的现实。同样的,正样本和负样本在序列特征长度上也有着明显的区别,而如果只从序列特征的长度就能得到预测结果,为什么我们不直接使用规则来进行匹配呢?
营销算法和推荐算法在这种样本层面的差异还是很大的,毕竟前者的样本是实打实的钱。小样本和样本不平衡带来了很多挑战,这些挑战也同样限制了前面提到的模型选择。
写在最后
写在从业近一年之际,深知我接触到的所谓机器学习只是沧海一粟。曾经有人说金融科技的营销算法完全不能称之算法工程师,只能算是数据分析。以我这些时间的认知,恐怕无法对此予以否认,不过出于一点小小的虚荣心,我还是在领英上称自己为Machine Learning Engineer,哈哈哈哈。
2025/5/25 于苏州